
[ad_1]
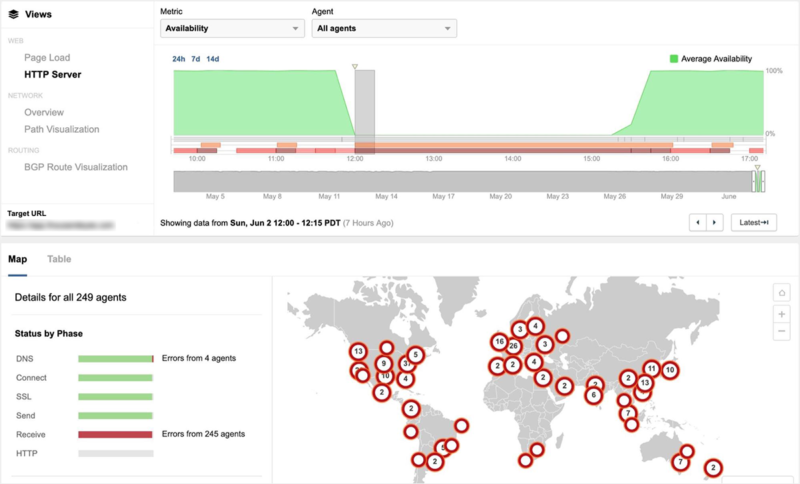
Enlarge / The outage started shortly after 12pm on June 2nd, impacting global users connecting to GCP us-east4-c. (credit: ThousandEyes)
{kind=link}
Earlier this week, the Internet had a conniption. In broad patches around the globe, YouTube sputtered. Shopify stores shut down. Snapchat blinked out. And millions of people couldn’t access their Gmail accounts. The disruptions all stemmed from Google Cloud, which suffered a prolonged outage—an outage which also prevented Google engineers from pushing a fix. And so, for an entire afternoon and into the night, the Internet was stuck in a crippling ouroboros: Google couldn’t fix its cloud, because Google’s cloud was broken.
The root cause of the outage, as Google explained this week, was fairly unremarkable. (And no, it wasn’t hackers.) At 2:45pm ET on Sunday, the company initiated what should have been a routine configuration change, a maintenance event intended for a few servers in one geographic region. When that happens, Google routinely reroutes jobs those servers are running to other machines, like customers switching lines at Target when a register closes. Or sometimes, importantly, it just pauses those jobs until the maintenance is over.
What happened next gets technically complicated—a cascading combination of two misconfigurations and a software bug—but had a simple upshot. Rather than that small cluster of servers blinking out temporarily, Google’s automation software descheduled network control jobs in multiple locations. Think of the traffic running through Google’s cloud like cars approaching the Lincoln Tunnel. In that moment, its capacity effectively went from six tunnels to two. The result: Internet-wide gridlock.
Read 12 remaining paragraphs | Comments
[ad_2]
Source link
Related Posts
- Cox Internet now charges $15 extra for faster access to online game servers
- Comcast usage soars 34% to 200GB a month, pushing users closer to data cap
- After White House stop, Twitter CEO calls congresswoman about death threats
- The sim swap the US isn’t using
- Probable Russian Navy covert camera whale discovered by Norwegians